Dimensional modeling is a technique for presenting analytic data, which has to be understandable by business users and query performance must be fast.
A model should always be simple in order to be easily understood by the business users and our BI colleagues. Usually when it starts simple, and the developer is happy and OCD-detailed, hopefully, will remain simple.
There are probably many types of models out there, but 2 are the most known ones.
– Star Schemas
– OLAP, also known as the ‘Cube‘
A Cube delivers super query performance, as it has already pre-aggregated the data and applied other optimizations too, and provides a more analytical option that is lacking with SQL. Commonly OLAP cubes are populated from a star schema.
There are two different parts that need to be combined: dimension & fact tables.
– Dimension tables contain descriptive information about measurements (such as sales amount). Each dimension is defined by a primary key, which serves as a constraint for non-duplicate data in a table and will be integrated with the Fact table.
The quality of a DWH is good if the dimension fields are descriptive enough. When you create a dimension, keep the used abbreviation codes by the business but also add a real meaning next to them.

If you already thinking to normalize data by storing the Brand on another table, the category on another one, and retrieving data through lookups/join-> stop there. Why? Normalizing doesn’t provide any improved efficiency and remember to … keep it simple!
– Fact tables contain the measurements associated with the performed business events of the company. Term fact represents a measure that is saved as a row in a table where data is on a specific level of detail, known as grain.

The above is an example of a sales transaction, stating how many products are sold on a specific date to a specific customer along with the generated sales amount. Usually, BI applications like the Cube retrieve all the rows from a fact table and perform pre-aggregations like adding all the sales amounts of the previous example. In some cases, there are some fields that can be semi-additive [such as account balances, which cannot be summed across the time dimension] or non-additive [such as unit prices].
The fact table has its own primary key, often called composite key, composed of a subset of the foreign keys.
Kimball’s Architecture
There are four parts that constitute a DWH/BI environment: source systems, ETL systems, presentation area and BI applications.
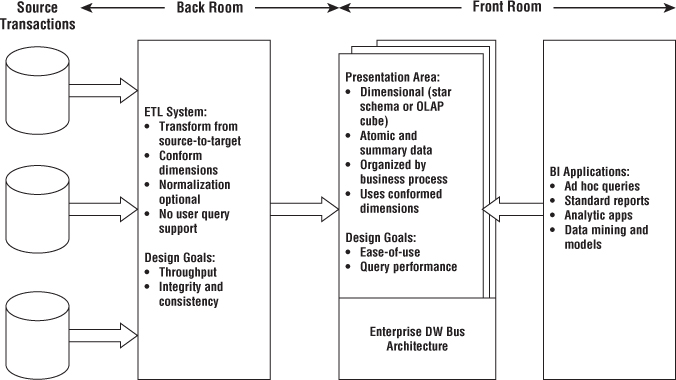
There are two alternative architectures to the Kimball architecture.
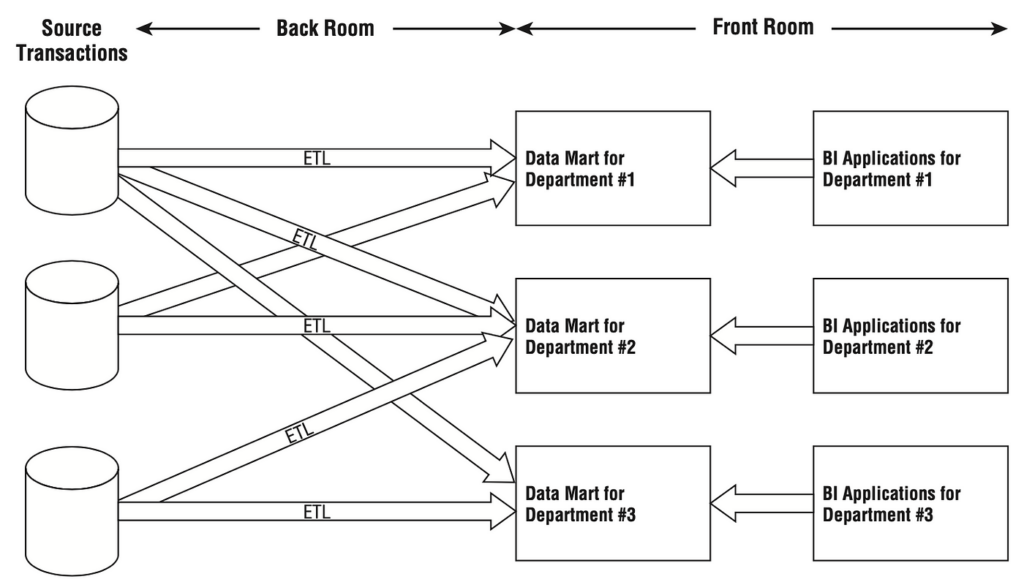
- Independent Data Mart: Each department of a company builds its own Data Mart, which contains similar but bit different data from other Data Marts. That would mean that multiple extracts are running from the same sources, which equals to un-needed spend of processing time and redundant storage
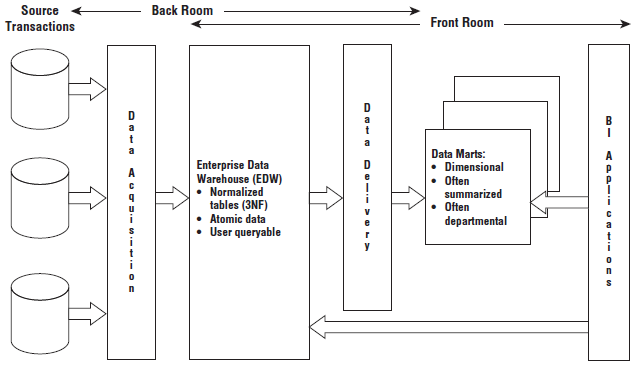
- Hub and Spoke Inmon Architecture: using the Corporate Information Factory approach data is extracted from the operational source systems and processed through the data acquisition layer (ETL system). Then the data lands in a 3NF database (normalized & atomic repo), referred to as the Enterprise Data Warehouse (EDW).
Dimensional design
– Gather business requirements
– Collaborate on dimensional modeling
– Dimensional design process: Select business process -> Declare grain ->Identify dimensions -> Identify facts.
– Star schemas and OLAP Cubes
Fact table techniques
– Fact table design: row corresponds to a measurement event, contains foreign keys and optional degenerate dimensions keys & DateTime stamps.
– Measure categories: Additive, Semi-Additive & Non-Additive facts
– Nulls: If there is an empty fact table foreign key, there should be a default row in the associated dimension table.
– Aggregate Fact tables or OLAP cubes: Cubes are meant to be accessed straight from the business users where aggregate fact tables are available to the BI layer.
– Surrogate key: a surrogate key is used as a single primary key of the fact table and serves as a fact table identifier.
Dimension techniques
– Dimension table design: Every table has a single primary key column, which is also embedded as a foreign key in the associated fact table.
– Dimension Surrogate key: are simple integer assigned in sequence starting with the value 1. Cannot be the source natural key because we won’t be able to track it over time.
– Multiple hierarchies: many hierarchies can exist in a dimension.
– Abbreviations & flags: should be replaced with full text in the dimension tables.
– Nulls: Should replace the null value with an [Unknown] or [Not Applicable].
– Date dimension: is attached to every fact table, so that business users can navigate through time. The primary key can be an integer representing YYYYMMDD, instead of a sequence key.
– Roleplay dimension: a fact table can be referenced more than once to a single physical dimension. For example, a fact table can have several dates such as Order date, Shipped date & Invoice date.
Slowly Changing Dimension Attributes
– Type 0 Retain original: Dimension attribute value never changes
– Type 1 Overwrite: New value overwrites the old value
– Type 2 Add new row: a new row is created with a generated primary key. Minimum 3 metadata columns should be added: StartDateTime, EndDateTime & Active row indicator
– Type 3 Add new attribute: a new attribute is added to preserve the old value.
Real-Time Fact
Lately, a lot of business is requesting almost real-time data, which that means that the fact table(s) needs to be updated more frequently. This desire can be implemented with a partitioning strategy or/and updates on OLAP cubes.
To be continued…